현재 진행하고 있는 도서 대출 서비스 앱에서 도서 정보를 DB에 등록해놔야 하는데, 나는 이 작업을 내가 수작업으로 하기 귀찮았다.
그리하여 파이썬을 이용해 데이터 크롤링으로 도서 정보를 가져오고, 해당 도서를 DB에 추가하려고 제작하였다.
또, 이러한 크롤링, DB에 정보 추가 작업을 내가 수작업으로(직접 파이썬을 실행시키고, 산출물을 DB에 추가하는 작업) 하기 싫어서, Github Action을 이용하여 CI / CD가 되도록 하였다.
계획
네이버북에서 책이름, ISBN, 저자 정보를 제공해주는 것을 확인 했고, URL에서 bid 값만 변경해주면 다른 책 정보를 확인 할 수 있는 것을 검토했다.
그럼 이제 해야할 일은 다음과 같다.
웹사이트 크롤링
크롤링한 정보 github에 issue 생성(제대로 크롤링 됐는지 확인하기 위함)
크롤링한 정보 DB에 추가
startNumber (bid 시작 값) 갱신
나는 이와 같은 작업을 매번 내가 수행하기 귀찮아서 Github Action을 이용하여 자동으로 크롤링하고, 이슈 등록하고, DB에 추가 후, startNumber를 갱신하는 action을 생성하였다.
이 게시물에서는 위 1,2 작업을 정리할 계획이다.
필요한 라이브러리
나는 크롤링을 위해, 또, DB 업로드를 위해 다음 라이브러리들을 사용하였다.
requests==2.27.1bs4==0.0.1selenium==4.1.5# 크롤링을 위해 넣은 라이브러리이나 BeautifulSoup를 쓰고 있어 안 쓰고 있다.
numpy==1.22.3pandas==1.4.2# 데이터 프레임으로 생성하여 테스트 하기 위해 넣었는데 내 크롤링에서 현재는 안 쓰는 라이브러리이다.
PyGithub==1.51pymysql==1.0.2
네이버북 화면
네이버북 홈페이지에 들어가보면 위와 같은 홈페이지가 나온다.
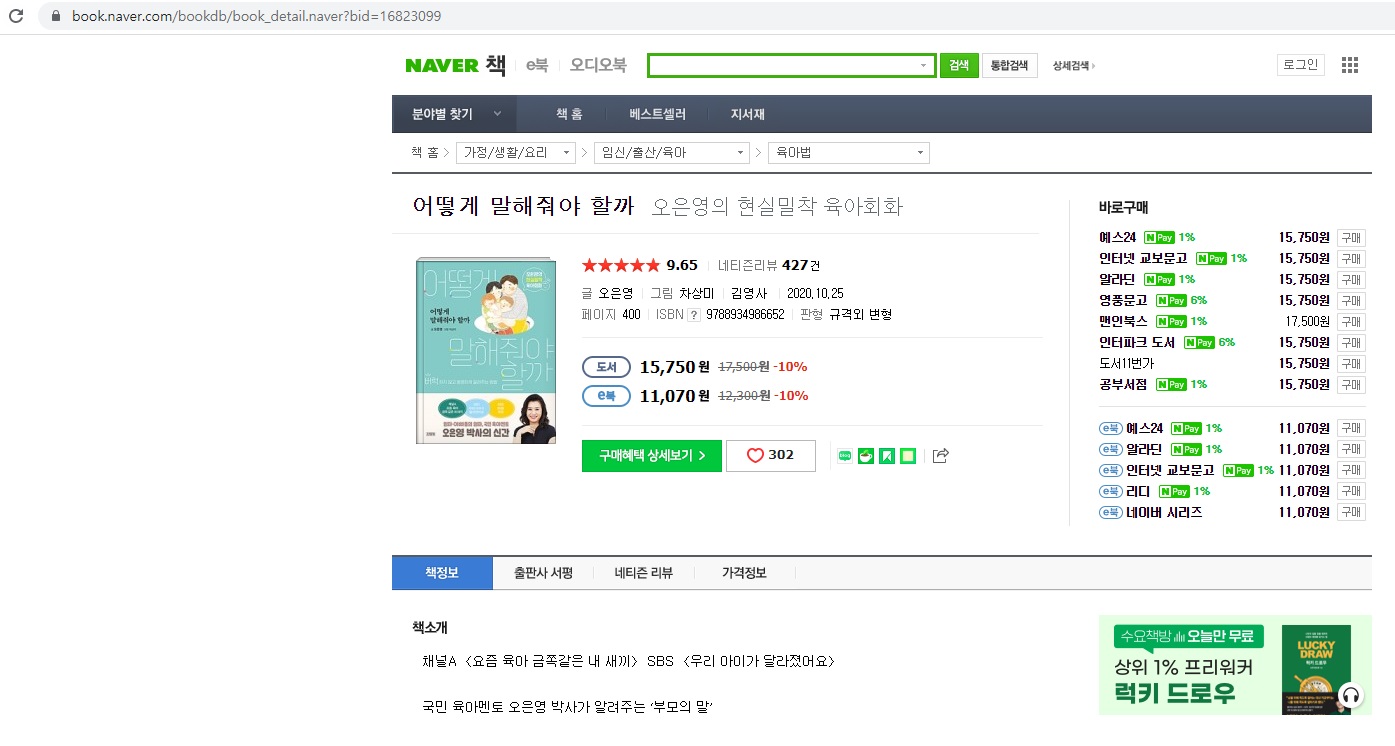
여기서 아무 책이나 눌러서 책의 정보를 확인해보았다.
책이름, ISBN, 저자 정보는 있는 것을 확인했으니 여러 책을 한 번에 크롤링 할 정도의 쉬운 URL인가를 확인해야 한다.
홈페이지 URL 정보를 보면 마지막에 bid=?????로 구성 되어있는 것을 확인 할 수 있다.
나는 여기서 ????에 있는 정수 부분만 바뀌면 다른 책의 정보가 뜰 것을 예상했고, 검색해본 결과 예상이 맞았다.
책정보 크롤링
defpage(index):returnrequests.get('https://book.naver.com/bookdb/book_detail.naver?bid='+str(index))defcrawler(i):response=page(i)soup=BeautifulSoup(response.content,"html.parser")### 책 이름 정보 가져옴
h2_tag=soup.findAll('h2')title=''fortaginh2_tag:title=str(tag.text).replace('\xa0',' ')### 책 저자, ISBN 정보 가져옴
writer=''isbn=''div_tag=soup.find('div',{'class':'book_info_inner'})fortagindiv_tag:if'|'intag.text:if'저자'intag.text:writer=tag.text.split('|')[0]writer=writer.split('저자 ')[1]writer=writer.replace('\xa0',' ')if'ISBN'intag.text:isbn=tag.text.split('|')[1]isbn=isbn.replace('ISBN','')isbn=isbn.strip()### book_info add
book_title.append(title)book_isbn.append(isbn)book_writer.append(writer)defmain(arg):startNumber=int(arg)foriinrange(startNumber,startNumber+100):crawler(i)
위와 같은 코드를 구성하였고, 여러 시행착오를 경험한 후 해당 코드가 책이름, 저자, isbn 정보를 잘 가져오는 것을 확인했다. - Github에서 소스 보기
파이썬에서 이슈 등록
fromgithubimportGithubdefget_github_repo(access_token,repository_name):"""
github repo object를 얻는 함수
:param access_token: Github access token
:param repository_name: repo 이름
:return: repo object
"""g=Github(access_token)repo=g.get_user().get_repo(repository_name)returnrepodefupload_github_issue(repo,title,body):"""
해당 repo에 title 이름으로 issue를 생성하고, 내용을 body로 채우는 함수
:param repo: repo 이름
:param title: issue title
:param body: issue body
:return: None
"""repo.create_issue(title=title,body=body)